CHAPTER6. 실제 시스템과의 조합
6.1. 시스템 개요
6.1.1. 배치 추천과 실시간 추천
- 아이템이나 사용자의 신규 추가 및 업데이트 빈도가 적고 업데이트 요구 수준이 비교적 낮을 때는 배치 추천이 적합함
6.1.2. 대표적인 추천 시스템 개요
개요 추천
- 개요 추천은 신규순이나 인기순으로 아이템을 표시하는 것으로 DB에 접근해 신규순으로 아이템을 정렬하는 쿼리를 실행하는 방법으로 할 수 있음
- 인기순으로 설계할 때는 인기도 집계를 수행하고 그 결과를 DB에 저장한 후 그 결과를 화면에 표시함
연관 아이템 추천
- 연관 아이템 추천 방법 중 하나는 사전에 유사도 계산하고 비슷한 아이템군을 DB에 저장해 결과를 반환하는 것임
- 유사 아이템 계산의 경우 행동 로그나 아이템의 콘텐츠 특징량 등을 사용할 수 있음
- 특정 사용자에게 보여서는 안되는 아이템을 제외하는 등의 처리를 하고 싶을 떄는 추천 API 안에 제외할 처리를 조합하면 쉬움(p194)
개인화 추천
- 배치 유형의 개인화 추천에서는 각 사용자별로 추천하는 아이템을 미리 계산해서 데이터베이스에 저장
- 웹 애플리케이션과 DB 사이에 추천 API를 끼워 넣어 아이템의 제외 로직 등을 조합하거나 A/B 테스트를 쉽게 수행할 수 있다는 것이 장점임
- 벡터 기반 개인화는 최근 많이 활용되는 방법으로 머신러닝 방법을 활용해 아이템과 사용자의 특징을 벡터화해서 DB에 저장하는 것

6.1.3. 다단계 추천
- 많은 상품, 사용자를 포함한 서비스에서 추천할 때는 시스템 부하를 고려해 설계해야 함
- 시스템 부하를 낮게 유지하면서 정밀도가 높은 추천을 수행하기 위해 후보 선택, 스코어링, 재순위 같은 다단계로 처리를 구분하는 방법이 활용됨(후보 선택과 스코어링/재순위의 2가지를 나눠 2단계 추천이라고 부름)
- 다단계 처리에서는 먼저 대략적으로 아이템 후보를 필터링한 뒤 아이템 후보 수가 줄어든 단계에서 사용자나 상황에 더 적합한 아이템을 높은 정확도의 모델로 엄선함
후보 선택
- 막대한 아이템으로부터 추천 후보가 될 아이템을 추출함
- 후보 선택 로직은 한 가지일 필요가 없으므로 여러 후보 선택 로직을 조합해 다양한 관점에서 후보 아이템을 추출할 수 있음
스코어링
- 스코어링은 실제로 사용자에게 제시할 아이템을 선택하기 위해 아이템에 점수를 부여함
- 이 스코어링 처리의 경우 후보 선택을 통해 스코어링 대상이 충분히 줄어 있으므로 머신러닝 모델에 의한 높은 정확도의 추론을 활용하는 경우가 많
- 여러 스코어링 처리에서는 500개의 후보가 있었을 때 대략적인 모델부터 정교한 모델을 다단계 순서로 적용해 100개, 50개, 25개로 후보를 필터링 함
재순위
- 재순위에서는 스코어링에서 선택된 아이템을 나열하도록 처리함
- 순위 정체의 균형을 고려해 비슷한 아이템만 나열되지 않도록 하거나 아이템 밀집도를 고려해 나열하도록 처리함
6.1.4. 근사 최근접 탐색
- 추천 시스템의 다양한 알고리즘은 공통적으로 사용자와 아이템을 벡터로 표현하고 해당 벡터의 유사도를 기반으로 추천을 수행함
- 근사 최근접 탐색을 사용한 추천은 주로 2단계로 이루어짐(아이템(사용자)의 벡터에 인덱스를 붙임 -> 해당 인덱스를 사용해 사용자에게 추천 아이템을 추천)
- 사용자에게 아이템을 추천할 때는 먼저 사용자의 벡터가 어느 영역에 속하는지 계산하고 해당 영역 안의 아이템만 대상으로 유사도를 계산해 추천 아이템을 추출하기도 함
아이템과 사용자 벡터 모두를 일 단위로 생성하는 경우
- 행렬 분해나 item2vec 등의 추천 알고리즘을 동작시켜 아이템과 사용자의 벡터를 매일 새롭게 생성하는 경우를 생각해보면 매번 계산 결과가 달라질 수 있음(예를 들어, 행렬 분해에서는 같은 데이터를 사용한 경우라도 목적 함수의 최적화에 무작위성이 있다면 같은 벡터를 얻는다고 보장할 수 없음)
- 따라서 아이템과 사용자 벡터 모두를 일 단위로 새롭게 생성하는 경우에는 근사 최근접 탐색에서 인덱스도 일 단위로 붙어야 함
사용자 벡터만 일 단위로 생성하는 경우
- 계산 속도나 서버 비용 관점에서 어려울 떄는 사용자 벡터만 일 단위로 업데이트하는 방법을 고려할 수 있음
- 주 단위로 다음을 처리: 아이템 벡터를 생성, 아이템 벡터에 인덱스를 붙임
- 일 단위로 다음을 처리: 사용자 벡터를 생성, 인덱스를 사용해 사용자에게 추천 아이템을 추천
- 아이템 벡터는 주 1회만 생성하므로 새로운 아이템은 다음번 처리 떄까지 추천할 수 없다는 점이 문제가 됨
모델을 유지하고 일 단위로 벡터를 생성하는 경우
- 가장 먼저 다음을 처리: 아이템과 사용자 벡터를 생성하고 이떄의 모델을 저장, 아이템 벡터에 인덱스를 붙임
- 일 단위로 다음을 처리: 저장한 모델을 사용해 아이템과 사용자의 벡터를 생성, 신규 아이템 벡터에 인덱스를 붙임, 그 인덱스를 사용해 사용자에게 추천 아이템을 추천
- 기존 아이템에는 계속 같은 인덱스가 붙으므로 추천 정확도가 떨어질 우려가 있어 추천 시스템에서는 앞의 2가지 방법을 많이 사용함
- 실무에서 근사 최근접 탐색을 사용할 때는 인덱스를 어떤 시점에 붙이는 것이 좋을지 검토한 후 전체 설계를 진행해야 함
- 근사 최근접 탐색 방법으로는 LSH, NMSLIP, Faiss, Annoy가 있으며 무엇을 사용할지는 자사의 데이터 크기나 서버 성능에 따라 적합한 방법을 선택해야 함

6.2. 로그 설계
6.2.1. 클라이언트 사이드 로그
- 클라이언트 사이드 로그는 사용자가 어떤 아이템을 열람하고 어떤 아이템을 클릭했는가처럼 사용자 행동에 잉르기까지의 경과나 결과를 기록하는 것이 주 목적임
사용자 행동
- 클라이언트 사이드 로그에서 대표적인 것이 행동 로그임
성능
- 성능은 사용자가 요청한 페이지가 실제로 완전히 표시될 때까지 걸리는 시간 또는 조작이 가능해질 때까지의 시간을 나타냄
에러와 크래시
- 에러 수에 관한 경고를 설정하는 것이 좋음
6.2.2. 서버 사이드 로그
- 서버 사이드 로그는 클라이언트 뒤쪽의 시스템 동작을 기록한 로그
성능
- 서버 사이드의 성능과 관련된 로그는 클라이언트로부터의 요청에 응답하는 데 걸리는 시간을 기록함
시스템 응답
- 클라이언트로부터의 요청 수나 응답 수 또는 정상 응답 비율을 기록함
- 예를 들어 연관 아이템 요청에 대해 반환하는 연관 아이템이 존재하지 않는 경우 로그를 남김으로써 추천 범위를 나타내는 지표인 커버리지를 측정할 수 있음
시스템 처리 정보
- 캐시의 히트 비율, CPU 부하, 메모리 사용률, 발생한 에러나 예외 수 등 시스템 처리 경과나 상황을 기록함
6.2.3. 사용자 행동 로그의 구체적인 예

6.3. 실제 시스템 예
6.3.1. 배치 추천

후보 기사 선정
- 추천 후보가 되는 기사를 선택함
- 기사의 최신성이 중요하므로 기사가 투고된 후 N일 이내의 기사만 후보 기사로 필터링하고, 한 번이라도 과거에 푸시로 전송된 적이 있는 기사는 후보 기사에서 제외
모델링
- 모델링 처리에서는 사용자 특징과 기사 특징을 활용해 사용자가 푸시 기사를 열지, 안 열지 예측하는 모델을 구축함
- 모델 학습은 1일 1회, 기사의 신규 전송 수가 적은 야간에 수행하고 학습한 모델을 저장해 둠
스코어링
- 학습이 완료된 모델에 사용자 특징량과 기사 특징량을 입력하고 각 사용자의 각 후보 기사에 대한 점수를 계산한 후 이 점수를 DB에 저장
푸시 전송
- 푸시 전송 처리에서는 각 사용자에게 추천 기사를 전송
CHAPTER7. 추천 시스템 평가
7.1. 3가지 평가 방법
오프라인 방법
- 오프라인 평가로 실제 서비스상에서의 열람, 구매 등 사용자 행동 이력에서 얻은 과거의 로그를 사용해 모델의 예측 정밀도 등을 평가
온라인 평가
- 온라인 평가는 새로운 테스트 대상의 추천 모델이나 새로운 사용자 인터페이스를 일부 사용자에게 실제로 표시함으로써 평가를 수행
사용자 스터디
- 사용자 스터디에 의한 평가는 사용자에게 인터뷰나 설문을 하는 것으로 추천 모델이나 사용자 인터페이스의 정성적인 성질을 조사
7.2. 오프라인 평가
7.2.1. 모델 정밀도 평가
- 추천 시스템에서 모델의 주요 목적은 과거의 사용자 행동을 학습하고 미지의 사용자 행동에 대해 높은 정밀도로 예측을 수행하는 것임
7.2.2. 모델 밸리데이션
- 시계열을 고려한 평가 데이터 분할 예는 아래와 같음

7.2.3. 모델 튜닝
- 파라미터 튜닝은 수동, 그리드 서치(각 파라미터의 후보를 미리 작성하고 각 파라미터의 모든 조합에 대해 평가를 수행하는 방법), 베이즈 최적화(파라미터 튜닝 정도에 따라 이전 검증 결과를 사용해 이후의 파라미터를 베이즈 확률 프레임에서 선택하는 방법)를 통해 수행할 수 있음
7.2.4. 평가 지표

- Precision은 예측 아이템 집합 안에 존재하는 적합 아이템의 비율임(적합 아이템 집합과 예측 아이템 집합의 교집합/순위의 길이)
- Recall은 예측 아이템 집합의 요소가 얼마나 적합 아이템 집합의 요소를 커버할 수 있는가의 비율(적합 아이템 집합과 예측 아이템 집합의 교집합/적합 아이템 집합)
- F1-measure은 Precision과 Recall의 조화 평균
7.2.4. 순위 평가 지표
- PR곡선은 가로축이 Recall, 세로축이 Precision으로 오른쪽 위로 위치할수록 정밀도가 높은 추천이라고 할 수 있음

MRR@K
- MRR@K(Mean Reciprocal Rank)는 사용자 순위에 대해 최초의 적합 아이템이 순위에서 얼마나 상위에 위치하는지 평가하는 지표임(예를 들어 사용자 u에게 제시한 순위에서 최초의 적합 아이템 위치가 2번째인 경우 k_u=2가 됨)
- 순위의 12번째에서 적합한 것보다 2번째에세 적합한 것이 평가 지표에 더 크게 기여함

AP@K
- AP@K(Average Precision)는 순위의 K번째까지에 대해 각 적합 아이템까지의 Precision을 평균한 값임
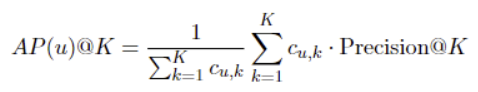
- 사용자 u에 대한 순위의 5번쨰 이내 아이템에서 2번째 아이템과 4번쨰 아이템 2개가 적합한 경우 다음과 같이 계산함

MAP@K
- MAP@K(Mean Average Precision)는 AP를 각 사용자에 대해 평균한 값
nDCG
- 지금까지 소개한 순위 지표는 클릭 유무와 같은 두 값에 대한 지표임
- 서비스에 따라서는 각 아이템이 클릭된 후의 구매 유무 등 클릭 이외의 행동까지 합쳐서 가중치를 붙여 여러 값을 평가하고 싶은 상황도 있음
- 이때 사용할 수 있는 것이 nDCG 임
7.2.5. 기타 지표
- 정밀도만 추구하는 것은 비슷한 상품만 추천해버리는 필터 버블 문제를 비롯해 서비스에서 바람직하지 않은 부작용을 일으킬 위험이 있음
카탈로그 커버리지
- 실제로 추천된 아이템 집합/모든 아이템 집합으로 구할 수 있으며, 추천 범위를 측정하는 지표임
사용자 커버리지
- 실제로 추천이 수행된 사용자 집합/모든 사용자 집합으로 구할 수 있으며, 어느 정도의 사용자에게 추천되었는지를 측정하는 지표임
- 사용자 커버리지는 콜드 스타트 문제 검출에 사용할 수 있음(커버리지가 낮을 경우 초기 사용자에 대해 추천이 수행되지 않는 콜드 스타트 문제가 발생했다는 것을 의미함)
신규성
- 신규성은 순위에 대한 추천 아이템이 정말로 새로운지를 나타냄

다양성
- 순위의 각 아이템 간 유사도 거리가 먼 경우 다양성이 커진다고 볼 수 있음

흥미로움
- 순위에 대해 의외성을 가지면서도 유용한 아이템의 비율을 측정(사용자 스터디를 통해 구할 수 있음)

7.3. 온라인 평가
- 시스템의 변경점을 실제로 사용자에게 제시해 평가하는 방법을 온라인 평가라고 부름
7.3.1. A/B 테스트
- A/B 테스트는 무작위 비교 시험이라고 불리는 평가 방법 중 하나임
- 테스트 대상의 기능에 변경을 추가한 결과를 보여주는 Treatment 그룹과 변경하지 않은 결과를 보여주는 Control 그룹의 2개 그룹으로 사용자를 나눈 후 평가를 수행하는 방법임
- A/B 테스트는 실제 사용자에게 변경점을 보여주므로 사용자 만족도를 저하시킬 수 있음 -> 먼저 적은 수의 사용자에게 실시할 내용이 의도대로 동작하는지 확인하는 것이 좋음
- 그룹 편향이나 집계 기간에 주의해야
7.3.1.1. 가설
- A/B 테스트를 시작할 떄는 테스트 대상의 효과에 대해 가설을 세우는 것이 좋음

7.3.1.2. 지표의 역할
OEC 지표
- A/B 테스트의 성공과 실패를 최종적으로 판단하는 지표
- 사용자 만족도를 측정하는 지표: Happiness(만족도, 시각적 매력, 쉬운 사용성 등), Engagement(서비스 실행 빈도, 인터랙션 깊이 등), Adoption(신규 사용자), Retention(서비스 사용 지속), Task success(효율성, 유효성, 에러율)
가드레일 지표
- 가드레일 지표는 저하되어서는 안 되는 제약을 표시함
- 페이지 열람 수, 서비스 가동률, 응답 속도, 주간 엑티브 사용자 수, 수익금 등이 있음
- 서비스 내 개인화 모듈의 클릭 정밀도가 향상된 결과로 연관 아이템 모듈의 클릭 수가 감소하는 일 등이 자주 발생함
7.3.1.3. 지표 설계 방침
감도
- 지표는 감도가 좋아야 함
- 첫 번째는 업데이트에 대해 지표가 얼마나 빈번하게 변동하는가를 나타내는 이동 확률임(좋은 지표는 크게 변화할 확률이 적고 안정적으로 측정할 수 있음)
- 두 번째는 효과에 변동이 있을 때 그것을 얼마나 정확하게 특정할 수 있는 가를 나타내는 통계력임
신뢰성
- 지표는 신뢰성이 높아야 하며, 로그 사용과 실측값에 괴리가 있는 경우는 신뢰성이 낮다고 할 수 있음
효율성
- 지표는 효율이 좋은 의사 결정으로 연결되어야 함
- 3개월 후의 얻게 될 정확한 답보다 오늘 얻을 수 있는 대략적인 답이 훨씬 가치가 있음
- 코세라는 과정 자료의 인터랙션과 퀴즈 사용률을 과정 완주율의 대리 지표로 사용하고 있음
해석 가능성과 방향성
- 지표는 쉽게 해석할 수 있어야 하며 방향성이 비즈니스 목표와 연결되어야 함
7.3.2. 인터리빙 -> 좀 더 알아보기!
- 인터리빙은 A/B테스트와 같이 사용자그룹을 나누지 않고 평가 대상의 각 순위를 하나의 순위로 섞어 사용자에게 제시함
7.4. 사용자 스터디를 통한 평가
- 오프라인과 온라인에서의 추천 시스템 평가 방법은 '실제로 사용자가 추천 시스템을 어떻게 느끼고 있는가'와 같이 서비스에 있어서 중요한 관점이 부족함
- 사용자에게 직접 인터뷰나 설문 조사를 실시하는 사용자 스터디를 통해 추천 시스템이 사용자에게 어떤 느낌을 주는지에 관한 시사점을 얻을 수 있음
- 아래와 같은 항목으로 사용자 스터디를 진행할 수 있음

출처: 가자마 마사히(2023). 추천 시스템 입문.
'추천시스템' 카테고리의 다른 글
| [추천 시스템 입문] 동영상 추천에서 중요한 요소 (0) | 2023.06.11 |
|---|---|
| [추천 시스템 입문] 추천 알고리즘 종류 (5) | 2023.06.10 |
| [추천 시스템 입문] 추천 시스템 소개와 UI/UX (0) | 2023.06.10 |
