5. 합성곱 신경망
5.1 합성곱 신경망
5.1.1 합성곱의 필요성
- 합성곱 신경망은 이미지나 영사을 처리하는 데 유용함
- 예를 들어 이미지 분석은 3x3배열을 펼쳐서(flattening) 각 픽셀에 가중치를 곱하여 은닉층에 전달하게 됨
5.1.2 합성곱 신경망 구조
- 합성곱 신경망(Convolutional Neural Netwok, CNN)은 음성 인식이나 이미지/영상 인식에서 주로 사용되는 신경망
- 다차원 배열 데이터를 처리하도록 구성되어 컬러 이미지 같은 다차원 배열 처리에 특화되어 있음
- 합성곱 신경망은 합성곱층과 풀링층을 거치면서 입력 이미지의 주요 특성 벡터를 추출함

입력층
- 입력층은 입력 이미지 데이터가 최초로 거치게 되는 계층이며, 단순 1차원의 데이터가 아닌 높이(height), 너비(width), 채널(channel)의 값을 갖는 3차원 데이터임
합성곱층
- 합성곱층(convolutional layer)은 입력 데이터에서 특성을 추출하는 역할을 수행
- 이미지에 대한 특성을 감지하기 위해서는 커널(kernel)이나 필터를 사용
- 커널/필터는 이미지의 모든 영역을 훑으면서 특성을 추출하게 되는데 이렇게 추출된 결과물이 특성 맵(feature map)이라고 함
- 커널은 일반적으로 3*3, 5*5 크기로 적용되는 것이 일반적이며, 스트라이드(stride)라는 지정된 간격에 따라 순차적으로 이동함
- 필터 채널이 3인 경우 필터 개수도 3개로 생각하기 쉽지만 실제로는 필터 개수가 1개임

풀링층
- 풀링층(pooling layer)은 합성곱과 유사하게 특성 맵의 차원을 다운 샘플링(이미지 축소)하여 연산량을 감소시키고, 주요한 특성 벡터를 추출하여 학습을 효과적으로 할 수 있게 함
- 풀링 연산에는 두 가지 방법이 사용되는데 최대 풀링(대상 영역에서 최댓값 추출), 평균 풀링(대상 영역에서 평균을 반환)이 있음
- 대부분의 합성곱 신경망에서는 최대 풀링이 사용되는데 평균 풀링은 각 커널 값을 평균화시켜 중요한 가중치를 갖는 값의 특성이 희미해질 수 있기 때문임

완전연결층
- 합성곱층과 풀링층을 거치면서 차원이 축소된 특성 맵은 최종적으로 완전연결층에 전달됨
- 이 과정에서 이미지는 3차원 벡터에서 1차원 벡터로 펼쳐지게 됨

출력층
- 출력층에서는 소프트맥스 활성화 함수가 사용되는데 입력받은 값을 0~1 사이의 값으로 출력함
- 마지막 출력층의 소프트맥스 함수를 사용하여 이미지가 각 레이블에 속할 확률 값이 출력됨
5.1.3 1D, 2D, 3D 합성곱
1D 합성곱
- 1D 합성곱은 필터가 시간을 축으로 좌우로만 이동할 수 있는 합성곱임
2D 합성곱
- 2D 합성곱은 필터가 두 개의 방향으로 움직이는 형태임
3D 합성곱
- 3D 합성곱은 필터가 움직이는 방향이 세 개임
3D 입력을 갖는 2D 합성곱
- 입력이 3D 형태임에도 출력 형태가 3D가 아닌 2D 행렬을 취하는 것임(필터에 대한 길이가 입력 채녈의 길이와 같아야 함)
- 대표적인 사례로 LeNet-5와 VGG가 있음
1*1 합성곱
- 1*1 합성곱은 3D 형태로 입력됨
- 입력(W, H, L)에 필터(1, 1, L)를 적용하면 출력은 (W, H)가 됨
- 1*1 합성곱에 채널 수를 조정해서 연산량이 감소되는 효과가 있음
- 대표적인 사례로 GoogLeNet이 있음
5.2 합성곱 신경망 맛보기
참고) GPU 사용
- 하나의 GPU를 사용하기 위해서는 다음의 코드를 이용
device=torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model=Net()
model.to(device)- 사용하는 PC에서 nn.DataParallel을 이용하여 다수의 GPU를 사용할 수도 있음(이를 사용할 경우 배치 크기가 알아서 각 GPU로 분배되기 때문에 GPU 수만큼 배치 크기도 늘려 주어야 함)
라이브러리 호출
import numpy as np
import matplotlib.pyplot as plt
import torch
import torch.nn as nn
from torch.autograd import Variable
import torch.nn.functional as F
import torchvision
import torchvision.transforms as transforms
from torch.utils.data import Dataset, DataLoader
데이터셋 내려받기
- transform을 통해 이미지를 텐서(0~1)로 변경
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")train_dataset = torchvision.datasets.FashionMNIST("FashionMNIST/", download=True, transform=
transforms.Compose([transforms.ToTensor()]))
test_dataset = torchvision.datasets.FashionMNIST("FashionMNIST/", download=True, train=False, transform=
transforms.Compose([transforms.ToTensor()]))
데이터로더에 전달
train_loader = torch.utils.data.DataLoader(train_dataset,
batch_size=100)
test_loader = torch.utils.data.DataLoader(test_dataset,
batch_size=100)
데이터 확인
# 텐서 데이터 확인하는 법
import numpy as np
exam = np.arange(0,500,3)
exam.resize(3,5,5)
print(exam)
exam[2][0][3]
--------------------------------------------------
[[[ 0 3 6 9 12]
[ 15 18 21 24 27]
[ 30 33 36 39 42]
[ 45 48 51 54 57]
[ 60 63 66 69 72]]
[[ 75 78 81 84 87]
[ 90 93 96 99 102]
[105 108 111 114 117]
[120 123 126 129 132]
[135 138 141 144 147]]
[[150 153 156 159 162]
[165 168 171 174 177]
[180 183 186 189 192]
[195 198 201 204 207]
[210 213 216 219 222]]]
159
참고) 객체
- 파이토치의 근간은 C++이며, 그에 따라 파이토치에서도 객체 지향 프로그램의 특징을 사용함(대표적으로 객체)
- 객체 지향 프로그래밍(object oriented programming)은 프로그래밍에서 필요한 데이터를 추상화하여 속성이나 행동, 동작, 특징 등을 객체로 만들고, 그 객체들이 서로 유기적으로 동작하도록 하는 방법임
- 클래스라는 붕어빵 틀에서 여러 개의 객체라는 붕어빵을 찍어내게 됨
참고) 클래스와 함수
- 함수란 하나의 특정 작업을 수행하기 위해 독립적으로 설계된 프로그램 코드
- 함수를 포함한 프로그램의 코드를 재사용하기 위해서는 함수뿐만 아니라 데이터가 저장되는 변수까지도 관리되어야 함
- 이와 같이 함수와 변수까지 한꺼번에 관리하고 재사용할 수 있게 해주는 것이 클래스임
심층 신경망 모델 생성
- torch.nn.Dropout(p)는 p만큼의 비율로 텐서의 값이 0이 되는 것임(0이 되지 않는 값들은 기존 값에 (1/(1-p))만큼 곱해짐
class FashionDNN(nn.Module):
def __init__(self):
super(FashionDNN,self).__init__() # FashionDNN이라는 부모 클래스를 상속받겠다는 의미
self.fc1 = nn.Linear(in_features=784,out_features=256)
self.drop = nn.Dropout2d(0.25)
self.fc2 = nn.Linear(in_features=256,out_features=128)
self.fc3 = nn.Linear(in_features=128,out_features=10)
def forward(self,input_data):
out = input_data.view(-1, 784) # view는 넘파이의 reshpe와 같은 역할로 텐서의 크기를 변경(-1, 784) -> (?, 784)
out = F.relu(self.fc1(out))
out = self.drop(out)
out = F.relu(self.fc2(out))
out = self.fc3(out)
return out
- 활성화 함수는 두 가지 방법으로 지정이 가능하며 forward() 함수에서는 F.relu(), __ init__() 함수에서는 nn.ReLU()
- F.relu(): forward() 함수에서 정의 / nn.ReLU(): __init__() 함수에서 정의
- nn.Conv2d에서는 input_channel과 output_channel을 사용해서 연산했다면 functional.conv2d는 입력과 가중치 자체를 직접 넣어줌(가중치를 전달해야 할 때마다 가중치 값을 새로 정의)
심층 신경망을 이용한 모델 학습
- 모델이 데이터를 처리하기 위해서는 모델과 데이터가 동일한 장치에 있어야 함
- Autograd는 자동 미분을 수행하는 파이토치의 핵심 패키지로 자동 미분에 대한 값을 저장하기 위해 테이프를 사용(순전파 단계에서는 테이프는 수행하는 모든 연산을 저장하고, 역전파 단계에서는 저장된 값들을 꺼내서 사용)
- Autograd는 Variable을 사용해서 역전파를 위한 미분 값을 자동으로 계산해 줌
심층 신경망에서 필요한 파라미터 정의
learning_rate = 0.001;
model = FashionDNN();
model.to(device)
criterion = nn.CrossEntropyLoss();
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate);
print(model)
--------------------------------------------------
FashionDNN(
(fc1): Linear(in_features=784, out_features=256, bias=True)
(drop): Dropout2d(p=0.25, inplace=False)
(fc2): Linear(in_features=256, out_features=128, bias=True)
(fc3): Linear(in_features=128, out_features=10, bias=True)
)
심층 신경망을 이용한 모델 학습
num_epochs = 5
count = 0
loss_list = []
iteration_list = []
accuracy_list = []
predictions_list = []
labels_list = []
for epoch in range(num_epochs):
for images, labels in train_loader:
images, labels = images.to(device), labels.to(device)
train = Variable(images.view(100, 1, 28, 28))
labels = Variable(labels)
outputs = model(train)
loss = criterion(outputs, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
count += 1
if not (count % 50):
total = 0
correct = 0
for images, labels in test_loader:
images, labels = images.to(device), labels.to(device)
labels_list.append(labels)
test = Variable(images.view(100, 1, 28, 28))
outputs = model(test)
predictions = torch.max(outputs, 1)[1].to(device)
predictions_list.append(predictions)
correct += (predictions == labels).sum()
total += len(labels)
accuracy = correct * 100 / total
loss_list.append(loss.data)
iteration_list.append(count)
accuracy_list.append(accuracy)
if not (count % 500):
print("Iteration: {}, Loss: {}, Accuracy: {}%".format(count, loss.data, accuracy))
--------------------------------------------------
Iteration: 500, Loss: 0.5817261338233948, Accuracy: 83.20999908447266%
Iteration: 1000, Loss: 0.472025990486145, Accuracy: 84.69999694824219%
Iteration: 1500, Loss: 0.3671049177646637, Accuracy: 84.80999755859375%
Iteration: 2000, Loss: 0.36796635389328003, Accuracy: 85.72999572753906%
Iteration: 2500, Loss: 0.26423969864845276, Accuracy: 86.57999420166016%
Iteration: 3000, Loss: 0.26001831889152527, Accuracy: 86.38999938964844%
torch.max(outputs, 1)이 있는데 1의 의미를 파악하기 위해 아래와 같이 실행해봄
import torch
import torch.nn as nn
data = torch.randn((5, 5))
print(data)
print(torch.max(data))
print(torch.max(data, 1))
--------------------------------------------------
tensor([[ 0.4534, -0.7466, 0.3465, 0.6455, -0.8765],
[ 0.6412, -1.5858, 0.2232, -0.1471, -0.9211],
[ 1.2993, -0.2697, 0.9602, -0.9422, 0.8010],
[-1.5591, -0.0076, 1.2083, 1.5805, -0.0050],
[ 0.5771, 0.9593, -0.5919, -0.1729, -0.1015]])
tensor(1.5805)
torch.return_types.max(
values=tensor([0.6455, 0.6412, 1.2993, 1.5805, 0.9593]),
indices=tensor([3, 0, 0, 3, 1]))
지금까지 심층 신경망에 대한 모델 생성과 성능을 평가해 보았기 때문에 이제는 합성곱 신경망을 생성하고 평가하기!
합성곱 네트워크 생성
- out_channels이 클수록 복잡한 성질을 학습할 수 있지만 파라미터 수가 증가한다는 단점이 있음
class FashionCNN(nn.Module):
def __init__(self):
super(FashionCNN, self).__init__()
self.layer1 = nn.Sequential(
nn.Conv2d(in_channels=1, out_channels=32, kernel_size=3, padding=1), #합성곱 연산을 통해 이미지의 특징을 추출
nn.BatchNorm2d(32), # 평균은 0, 표준편차 1로 데이터의 분포 조정
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2) # stride는 이동 간격
)
self.layer2 = nn.Sequential(
nn.Conv2d(in_channels=32, out_channels=64, kernel_size=3),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.MaxPool2d(2)
)
self.fc1 = nn.Linear(in_features=64*6*6, out_features=600) # 클래스를 분류하기 위해서는 이미지 형태의 데이터를 배열 형태로 변환
self.drop = nn.Dropout2d(0.25)
self.fc2 = nn.Linear(in_features=600, out_features=120)
self.fc3 = nn.Linear(in_features=120, out_features=10)
def forward(self, x):
out = self.layer1(x)
out = self.layer2(out)
out = out.view(out.size(0), -1) # 합성곱층에서 완전연결층으로 변경되기 때문에 데이터의 형태를 1차원으로 바꾸어 주어야 함(열의 수를 알지 못할 때 -1)
out = self.fc1(out)
out = self.drop(out)
out = self.fc2(out)
out = self.fc3(out)
return outConv2d 계층에서의 출력 크기 구하는 공식
- 출력 크기=(W-F+2P)/S+1
- W: 입력 데이터의 크기
- F: 커널 크기
- P: 패딩 크기
- S: 스트라이드
MaxPool2d 계층에서의 출력 크기 구하는 공식
- 출력 크기=IF/F
- IF: 입력 필터의 크기
- F: 커널 크기
사용하고 있는 데이터로 계산
- self.layer1
- Conv2d (28-3+2)/1+1 = 28
- MaxPool2d 28/2 = 14
- self.layer2
- Conv2d (14-3)/1+1 = 12
- MaxPool2d 12/2 = 6 ---> self.fc1에서 in_features=64*6*6인 이유(64는 channels의 수)
힙성곱 네트워크를 위한 파라미터 정의
learning_rate = 0.001;
model = FashionCNN();
model.to(device)
criterion = nn.CrossEntropyLoss();
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate);
print(model)
--------------------------------------------------
FashionCNN(
(layer1): Sequential(
(0): Conv2d(1, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
(3): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(layer2): Sequential(
(0): Conv2d(32, 64, kernel_size=(3, 3), stride=(1, 1))
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
(3): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(fc1): Linear(in_features=2304, out_features=600, bias=True)
(drop): Dropout2d(p=0.25, inplace=False)
(fc2): Linear(in_features=600, out_features=120, bias=True)
(fc3): Linear(in_features=120, out_features=10, bias=True)
)
모델 학습 및 성능 평가
num_epochs = 5
count = 0
loss_list = []
iteration_list = []
accuracy_list = []
predictions_list = []
labels_list = []
for epoch in range(num_epochs):
for images, labels in train_loader:
images, labels = images.to(device), labels.to(device)
train = Variable(images.view(100, 1, 28, 28))
labels = Variable(labels)
outputs = model(train) # 위에서 정의한 model 사용
loss = criterion(outputs, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
count += 1
if not (count % 50):
total = 0
correct = 0
for images, labels in test_loader:
images, labels = images.to(device), labels.to(device)
labels_list.append(labels)
test = Variable(images.view(100, 1, 28, 28))
outputs = model(test)
predictions = torch.max(outputs, 1)[1].to(device)
predictions_list.append(predictions)
correct += (predictions == labels).sum()
total += len(labels)
accuracy = correct * 100 / total
loss_list.append(loss.data)
iteration_list.append(count)
accuracy_list.append(accuracy)
if not (count % 500):
print("Iteration: {}, Loss: {}, Accuracy: {}%".format(count, loss.data, accuracy))
--------------------------------------------------
...
Iteration: 3000, Loss: 0.14295698702335358, Accuracy: 90.16999816894531%
5.3 전이학습
- 합성곱 신경망 기반의 딥러닝 모델을 제대로 훈련시키려면 많은 양의 데이터가 필요
- 많은 양의 데이터를 확보하기 위해서는 돈과 시간이 필요한데 이와 같은 현실적인 어려움을 해결한 것이 전이 학습(transfer learning)
- 전이 학습이란 이미지넷처럼 아주 큰 데이터셋을 써서 훈련된 모델의 가중치를 가져와 우리가 해결하려는 과제에 맞게 보정해서 사용하는 것을 의미함
- 전이 학습을 위한 방법으로는 특성 추출과 미세 조정 기법이 있음
5.3.1 특성 추출 기법
- 특성 추출(feature extractor)은 ImageNet 데이터셋으로 사전 훈련된 모델을 가져온 후 마지막 완전연결층 부분만 새롭게 만들게 됨
- 특성 추출을 위해서는 OpenCV(Open Source Computer Vision Library) 라이브러리 필요함

라이브러리 호출
import os
import time
import copy
import glob
import cv2
import shutil
import torch
import torchvision
import torchvision.transforms as transforms
import torchvision.models as models
import torch.nn as nn
import torch.optim as optim
import matplotlib.pyplot as plt
이미지 데이터 전처리 방법
- 데이터로더에서 new_workers는 하위 프로세스를 몇 개 사용할지 설정하는 것임(너무 많은 하위 프로세스를 설정하게 되면 오류가 발생하거나 메모리 부족 현상이 발생할 수 있음)
from google.colab import files # 데이터 불러오기
file_uploaded=files.upload() # 데이터 불러오기: chap05/data/catndog.zip 파일 선택
!unzip catanddog.zip -d catanddog/ #catanddog 폴더 만들어 압축 풀기
data_path = 'catanddog/train/'
transform = transforms.Compose(
[
transforms.Resize([256, 256]),
transforms.RandomResizedCrop(224), # 이미지를 랜덤한 크기 및 배율로 자름
transforms.RandomHorizontalFlip(), # 이미지를 랜덤하게 수평으로 뒤집음
transforms.ToTensor(), # 이미지 데이터를 텐서로 변환
])
train_dataset = torchvision.datasets.ImageFolder(
data_path,
transform=transform # 위에서 정의한 전처리
)
train_loader = torch.utils.data.DataLoader(
train_dataset,
batch_size=32,
num_workers=8,
shuffle=True
)
print(len(train_dataset))
--------------------------------------------------
356
사전 훈련된 모델 내려받기
resnet18 = models.resnet18(pretrained=True) # pretrained=True는 사전 학습된 가중치를 사용하겠다는 의미
사전 훈련된 모델의 파라미터 학습 유무 지정
- ResNet18의 합성곱층을 사용하되 파라미터에 대해서는 학습을 하지 않도록 고정
def set_parameter_requires_grad(model, feature_extracting=True):
if feature_extracting:
for param in model.parameters():
param.requires_grad = False
set_parameter_requires_grad(resnet18)
ResNet18에 완전연결층 추가
resnet18.fc = nn.Linear(512, 2)
모델 객체 생성 및 손실 함수 정의
model = models.resnet18(pretrained = True) # 사전 훈련된 모델 내려받기(모델의 객체 생성)
for param in model.parameters(): # 모델의 합성곱층 가중치 고정
param.requires_grad = False # 역전파 중 파라미터들에 대한 변화를 계산할 필요가 없음(합성곱과 출링층에서)
model.fc = torch.nn.Linear(512, 2) # 클래스가 2개이기 때문에 2로(512은 사전 훈련된 model에서 확인하는 거 같음)
for param in model.fc.parameters(): # 모델에 접근하여 파라미터 값들 가져오기
param.requires_grad = True # 완전연결층은 학습
optimizer = torch.optim.Adam(model.fc.parameters())
cost = torch.nn.CrossEntropyLoss()
모델 학습을 위한 함수 생성
- loss.item()에서 loss는 미니 배치로 평균 손실이 저장되어 있어 미니 배치의 크기인 input.size(0)를 곱해 미니 배치의 총 손실을 구하게 됨
def train_model(model, dataloaders, criterion, optimizer, device, num_epochs=13, is_train=True):
since = time.time() # 컴퓨터의 현재 시각을 구하는 함수
acc_history = []
loss_history = []
best_acc = 0.0
for epoch in range(num_epochs):
print('Epoch {}/{}'.format(epoch, num_epochs - 1))
print('-' * 10)
running_loss = 0.0
running_corrects = 0
for inputs, labels in dataloaders:
inputs = inputs.to(device)
labels = labels.to(device)
model.to(device)
optimizer.zero_grad() # 기울기를 0으로 설정
outputs = model(inputs) # 순전파 학습
loss = criterion(outputs, labels)
_, preds = torch.max(outputs, 1)
loss.backward() # 역전파 학습
optimizer.step()
running_loss += loss.item() * inputs.size(0)
running_corrects += torch.sum(preds == labels.data)
epoch_loss = running_loss / len(dataloaders.dataset)
epoch_acc = running_corrects.double() / len(dataloaders.dataset)
print('Loss: {:.4f} Acc: {:.4f}'.format(epoch_loss, epoch_acc))
if epoch_acc > best_acc:
best_acc = epoch_acc
acc_history.append(epoch_acc.item())
loss_history.append(epoch_loss)
torch.save(model.state_dict(), os.path.join('catanddog/', '{0:0=2d}.pth'.format(epoch))) # 모델 재사용을 위해 저장
print()
time_elapsed = time.time() - since # 학습 시간 계산
print('Training complete in {:.0f}m {:.0f}s'.format(time_elapsed // 60, time_elapsed % 60))
print('Best Acc: {:4f}'.format(best_acc))
return acc_history, loss_history
파라미터 학습 결과를 옵티마이저에 전달
- 마지막으로 ResNet18에 추가된 완전연결층은 학습을 하도록 설정
- 학습을 통해 얻어지는 파라미터를 옵티마이저에 전달해서 최종적으로 모델 학습에 사용
params_to_update = []
for name,param in resnet18.named_parameters():
if param.requires_grad == True:
params_to_update.append(param) # 파라미터 학습 결과를 저장
print("\t",name)
optimizer = optim.Adam(params_to_update) # 학습 결과를 옵티마이저에 전달
--------------------------------------------------
fc.weight
fc.bias
모델 학습
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
criterion = nn.CrossEntropyLoss()
train_acc_hist, train_loss_hist = train_model(resnet18, train_loader, criterion, optimizer, device)
--------------------------------------------------
...
Epoch 12/12
----------
Loss: 0.2190 Acc: 0.9169
Training complete in 0m 52s
Best Acc: 0.924675
테스트 데이터 호출 및 전처리
test_path = 'catanddog/test/'
transform = transforms.Compose(
[
transforms.Resize(224),
transforms.CenterCrop(224),
transforms.ToTensor(),
])
test_dataset = torchvision.datasets.ImageFolder(
root=test_path,
transform=transform
)
test_loader = torch.utils.data.DataLoader(
test_dataset,
batch_size=32,
num_workers=1,
shuffle=True
)
print(len(test_dataset))
--------------------------------------------------
98
테스트 데이터 평가 함수 생성
def eval_model(model, dataloaders, device):
since = time.time()
acc_history = []
best_acc = 0.0
saved_models = glob.glob('catanddog/' + '*.pth') # glob는 현재 디렉터리에서 원하는 파일만 가져올 때 사용
saved_models.sort()
print('saved_model', saved_models)
for model_path in saved_models:
print('Loading model', model_path)
model.load_state_dict(torch.load(model_path))
model.eval()
model.to(device)
running_corrects = 0
for inputs, labels in dataloaders:
inputs = inputs.to(device)
labels = labels.to(device)
with torch.no_grad():
outputs = model(inputs)
_, preds = torch.max(outputs.data, 1)
preds[preds >= 0.5] = 1
preds[preds < 0.5] = 0
running_corrects += preds.eq(labels).int().sum() # preds.eq(labels)는 preds배열과 labels가 일치하는지 검사하는 용도로 사용
epoch_acc = running_corrects.double() / len(dataloaders.dataset)
print('Acc: {:.4f}'.format(epoch_acc))
if epoch_acc > best_acc:
best_acc = epoch_acc
acc_history.append(epoch_acc.item())
print()
time_elapsed = time.time() - since
print('Validation complete in {:.0f}m {:.0f}s'.format(time_elapsed // 60, time_elapsed % 60))
print('Best Acc: {:4f}'.format(best_acc))
return acc_history
테스트 데이터를 평가 함수에 적용
val_acc_hist = eval_model(resnet18, test_loader, device)
--------------------------------------------------
...
Validation complete in 0m 15s
Best Acc: 0.948980
5.3.2 미세 조정 기법
- 미세 조정(fine-tuning) 기법은 특성 추출 기법에서 더 나아가 사전 훈련된 모델과 합성곱층, 데이터 분류기의 가중치를 업데이트하여 훈련시키는 방식임
- 특성 추출은 목표 특성을 잘 추출했다는 전제하에 좋은 성능을 낼 수 있음
- 특성이 잘못 추출되었다면 미세 조정 기법으로 새로운 이미지 데이터를 사용하여 네트워크의 가중치를 업데이트해서 특성을 다시 추출
- 데이터셋이 크고 사전 훈련된 모델과 유사성이 작을 경우: 모델 전체를 재학습
- 데이터셋이 크고 사전 훈련된 모델과 유사성이 클 경우: 합성곱층의 뒷부분과 데이터 분류기를 학습
- 데이터셋이 작고 사전 훈련된 모델과 유사성이 작을 경우: 합성곱층의 일부분과 데이터 분류기를 학습(데이터가 적기 때문에 일부 계층에 미세 조정 기법을 적용)
- 데이터셋이 작고 사전 훈련된 모델과 유사성이 클 경우: 데이터 분류기만 학습(데이터가 적기 때문에 많은 계층에 미세 조정 기법을 적용하면 과적합이 발생할 수 있음)

5.4 설명 가능한 CNN
- 설명 가능한 CNN은 딥러닝 처리 결과를 사람이 이해할 수 있는 방식으로 제시하는 기술임
5.4.1 특성 맵 시각화
- 특성 맵은 입력 이미지 또는 다른 특성 맵처럼 필터를 입력에 적용한 결과임
- 특정 입력 이미지에 대한 특성 맵을 시각화한다는 의미는 특성 맵에서 입력 특성을 감지하는 방법을 이해할 수 있도록 도움
필요한 라이브러리 호출
import matplotlib.pyplot as plt
from PIL import Image
import cv2
import torch
import torch.nn.functional as F
import torch.nn as nn
from torchvision.transforms import ToTensor
import torchvision
import torchvision.transforms as transforms
import torchvision.models as models
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
설명 가능한 네트워크 생성
- 로그 소프트맥스는 신경망 말단의 결괏값들을 확률 개념으로 해석하기 위해 소프트맥스 함수의 결과에 log 값을 취한 연산
- 소프트맥스를 사용하지 않고 로그 소프트맥스를 사용하는 이유는 소프트맥스는 기울기 소멸 문제에 취약하기 떄문
class XAI(torch.nn.Module):
def __init__(self, num_classes=2):
super(XAI, self).__init__()
self.features = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=3, bias=False),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True), # 기존의 데이터를 연산의 결괏값으로 대체하라는 의미
nn.Dropout(0.3),
nn.Conv2d(64, 64, kernel_size=3, padding = 1, bias=False),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(64, 128, kernel_size=3, padding = 1, bias=False),
nn.BatchNorm2d(128),
nn.ReLU(inplace=True),
nn.Dropout(0.4),
nn.Conv2d(128, 128, kernel_size=3, padding = 1, bias=False),
nn.BatchNorm2d(128),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(128, 256, kernel_size=3, padding = 1, bias=False),
nn.BatchNorm2d(256),
nn.ReLU(inplace=True),
nn.Dropout(0.4),
nn.Conv2d(256, 256, kernel_size=3, padding = 1, bias=False),
nn.BatchNorm2d(256),
nn.ReLU(inplace=True),
nn.Dropout(0.4),
nn.Conv2d(256, 256, kernel_size=3, padding = 1, bias=False),
nn.BatchNorm2d(256),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(256, 512, kernel_size=3, padding = 1, bias=False),
nn.BatchNorm2d(512),
nn.ReLU(inplace=True),
nn.Dropout(0.4),
nn.Conv2d(512, 512, kernel_size=3, padding = 1, bias=False),
nn.BatchNorm2d(512),
nn.ReLU(inplace=True),
nn.Dropout(0.4),
nn.Conv2d(512, 512, kernel_size=3, padding = 1, bias=False),
nn.BatchNorm2d(512),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(512, 512, kernel_size=3, padding = 1, bias=False),
nn.BatchNorm2d(512),
nn.ReLU(inplace=True),
nn.Dropout(0.4),
nn.Conv2d(512, 512, kernel_size=3, padding = 1, bias=False),
nn.BatchNorm2d(512),
nn.ReLU(inplace=True),
nn.Dropout(0.4),
nn.Conv2d(512, 512, kernel_size=3, padding = 1, bias=False),
nn.BatchNorm2d(512),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2),
)
self.classifier = nn.Sequential(
nn.Linear(512, 512, bias=False),
nn.Dropout(0.5),
nn.BatchNorm1d(512),
nn.ReLU(inplace=True),
nn.Dropout(0.5),
nn.Linear(512, num_classes)
)
def forward(self, x):
x = self.features(x)
x = x.view(-1, 512)
x = self.classifier(x)
return F.log_softmax(x)
모델 객체화
model=XAI()
model.cpu() #모델에 입력되는 이미지를 넘파이로 받아오는 부분때문에 CPU를 사용하도록 지정하였습니다
model.eval()
특성 맵을 확인하기 위한 클래스 정의(Conv2d(3, 64, kernel_size=(3,3), stride=(1, 1), bias=False)에 대한 특성 맵을 확인하기 위한 클래스 정의)
- 특성 맵은 합성곱층을 입력 이미지와 필터를 연산하여 얻은 결과
- 파이토치는 매 계층마다 print 문을 사용하지 않더라도 hook 기능을 사용하여 각 계층의 활성화 함수 및 기울기 값을 확인할 수 있음(register_forward_hook의 목적은 순전파 중에 각 네트워크 모듈의 입력 및 출력을 가져오는 것)
- 특정한 값으로 정의되지 않은 중간 변수에 대해서 파이토치는 기울기 값을 저장하지 않지만 z.register_hook(hook_fn)을 사용하면 기울기 값을 알 수 있음
class LayerActivations:
features=[]
def __init__(self, model, layer_num):
self.hook = model[layer_num].register_forward_hook(self.hook_fn)
def hook_fn(self, module, input, output):
output = output
self.features = output.detach().numpy()
def remove(self):
self.hook.remove()
이미지 호출
from google.colab import files # 데이터 불러오기
file_uploaded=files.upload() # chap05/data/cat.jpg 데이터 불러오기
img=cv2.imread("cat.jpg")
plt.imshow(img)
img = cv2.resize(img, (100, 100), interpolation=cv2.INTER_LINEAR)
img = ToTensor()(img).unsqueeze(0)
print(img.shape)
Conv2d 특성 맵 확인
result = LayerActivations(model.features, 0)
model(img)
activations = result.features
특성 맵 확인
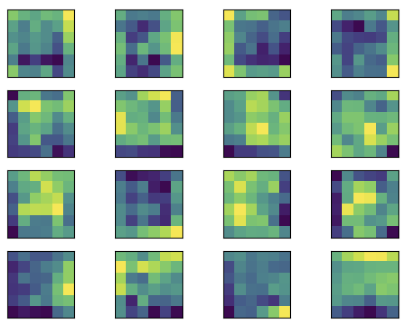
- 첫 번째 Conv2d 계층에서 특성 맵에 대한 출력 결과를 보면 입력 이미지의 형태가 많이 유지되고 있음을 알 수 있음
- 출력층에 가까울수록 원래 이미지 형태는 찾아볼 수 없으며, 이미지 특징들만 전달됨
fig, axes = plt.subplots(4,4)
fig = plt.figure(figsize=(12, 8))
fig.subplots_adjust(left=0, right=1, bottom=0, top=1, hspace=0.05, wspace=0.05)
for row in range(4):
for column in range(4):
axis = axes[row][column]
axis.get_xaxis().set_ticks([])
axis.get_yaxis().set_ticks([])
axis.imshow(activations[0][row*10+column])
plt.show()
5.5 그래프 합성곱 네트워크
5.5.1 그래프란
- 그래프는 방향성이 있거나 없는 에지로 연결된 노드의 집합임
- 여기서 노드와 에지는 일반적으로 풀고자 하는 문제에 대한 전문가 지식이나 직관 등으로 구성됨
5.5.2 그래프 신경망
- 그래프 신경망에서 인접행렬과 특성행렬은 다음과 같이 표현됨

5.5.3 그래프 합성곱 네트워크
- 그래프 합성곱 네트워크는 이미지에 대한 합성곱을 그래프 데이터로 확장한 알고리즘임
출처: 서지영(2022). 딥러닝 파이토치 교과서. p166-p244.
'파이토치' 카테고리의 다른 글
| [딥러닝 파이토치 교과서] 합성곱 신경망2 (0) | 2023.05.28 |
|---|---|
| [파이토치] 신경망 모델 구성/Autograd/최적화 (1) | 2023.05.14 |
| [딥러닝 파이토치 교과서] RNN, LSTM, GRU (0) | 2023.04.22 |
| [딥러닝 파이토치 교과서] 활성화함수와 손실 함수 (0) | 2023.04.16 |
| [딥러닝 파이토치 교과서] 머신러닝과 파이토치 (0) | 2023.04.07 |

